
- Giới thiệu
- Những giới hạn của fine-tuning thông thường
- Các Reward functions phổ biến trong NLP
- RL và LLM
- Kết luận
- 📚 Tham khảo
Giới thiệu
Reinforcement Learning (RL) là một nhánh quan trọng của học máy (machine learning), trong đó một tác tử (agent) học cách đưa ra hành động trong một môi trường bằng cách nhận các phần thưởng hoặc hình phạt từ những quyết định của mình. Trước đây, RL chủ yếu được ứng dụng trong robotic và nổi tiếng hơn cả là game playing, nơi mà RL đã tạo ra những đột phá như AlphaGo của DeepMind với khả năng vượt trội hơn cả con người. Gần đây, RL đang dần được ứng dụng rộng rãi hơn trong Xử lý Ngôn ngữ Tự nhiên (NLP), đặc biệt là trong việc align các mô hình ngôn ngữ lớn (LLMs) như ChatGPT thông qua RLHF (Reinforcement Learning from Human Feedback) hay dạy cách LLMs cách suy luận (reasoning) thông qua GRPO với Deepseek R1. Trong bài viết này, ta sẽ cùng khám phá cách RL áp dụng trong NLP, những ứng dụng liên quan của kỹ thuật này với hơi hướng đi sâu về technical.
Những giới hạn của fine-tuning thông thường
Trong fine-tuning thông thường, training objective được sử dụng là Maximum Likelihood để tối đa hoá xác suất xuất hiện của token tiếp theo, dựa trên những tokens đã xuất hiện trước đó. Kỹ thuật training này sẽ có một vài hạn chế:
- Task mismatch: ví dụ khi ta muốn train một LLMs để chúng đưa ra những response hữu ích và lịch sự, và objective này khó được encode một cách hiệu quả thông qua việc training với Maximum Likelihood. Một ví dụ khác là khi ta muốn models tạo sinh code đúng syntax của ngôn ngữ lập trình hay pass những test cases có sẵn,…
- Data mismatch: trong task phía trên, đôi khi training data từ những nguồn như Reddit sẽ chứa những instance mà ta không mong muốn (toxic comments,…)
- Exposure bias: model khi training, nếu chỉ được train trên correct response, sẽ thiếu đi khả năng xử lý lỗi trong test time. Khi sử dụng LLMs để xây dựng agents, ta sẽ mong đợi mô hình đó có khả năng recover from errors.
Từ đây, RL có thể được sử dụng để giúp phần nào giảm đi những hạn chế trên. Sau đây là một diagram minh hoạ cho quá trình RL training cho LLM:
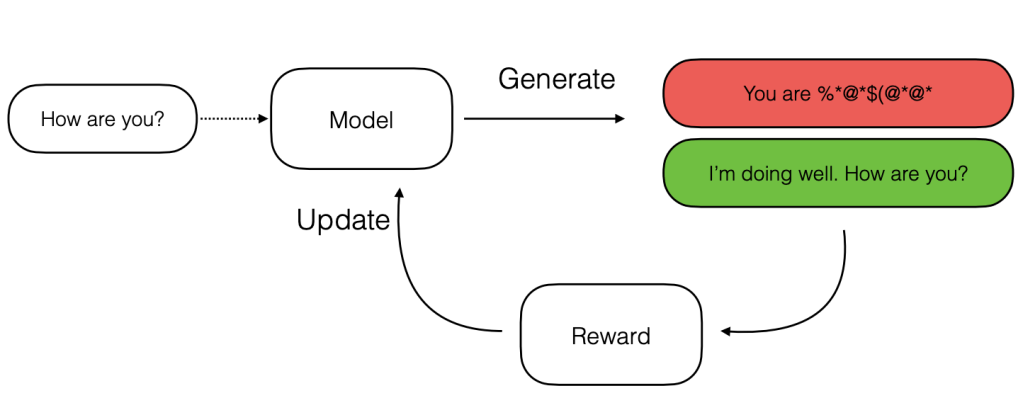
Một điểm mà ta có thể chú ý ngay đó là quá trình RL sẽ khác với training thông thường ở chỗ, ta không có data sẵn để train model mà sẽ sample outputs từ model hiện tại và dùng một reward function để tạo những learning signal rằng output A tốt hơn output B, và model nên ưu tiên tạo ra output A thay vì output B. Khi này, reward function (có thể là một LLM khác) sẽ thể hiện task criteria mà ta muốn optimize.
Nếu bạn có biết qua về policy optimization trong RL, setup này khá giống với thuật toán actor-critic, với LLM cần train là actor model và reward function đóng vai trò là critic model.
Các Reward functions phổ biến trong NLP
Trong RL training cho LLM, reward functions thường sẽ có 2 dạng:
- Rule-based rewards
- Model-based rewards
Rule-based rewards
Khi có một tính chất nào đó trên output mà ta có thể tự động kiểm tra và verify bằng code, ví dụ độ dài output hay tính chính xác đối với các vấn đề tính toán, ta có thể viết một hàm đơn giản nhận vào output từ LLM, trả về một giá trị nào đó và sử dụng nó như reward function.
Một ví dụ phức tạp hơn là khi ta muốn train một model để viết code sao cho pass tất cả test cases, ta có thể sử dụng số test cases passed khi chạy output code như một giá trị reward.
Hay một ví dụ khác, khi muốn khuyến khích model viết thơ với chỉ 5 dòng, ta có thể dùng reward function:

Nếu chỉ sử dụng objective phía trên, một cách đơn giản mà model có thể dùng để exploit là tạo ra output chỉ với 5 dòng thay vì viết thơ. Vì vậy, thường trong các objective function thực sự, người ta sẽ sử dụng thêm những regularization terms để tránh các failure modes như này.
Model-based rewards
Ở đây, reward function có thể là một machine learning model, hay hiện nay người ta thường sử dụng một LLM khác được fine-tune để đóng vai trò này. Có 2 cách để sử dụng LLM như một reward model:
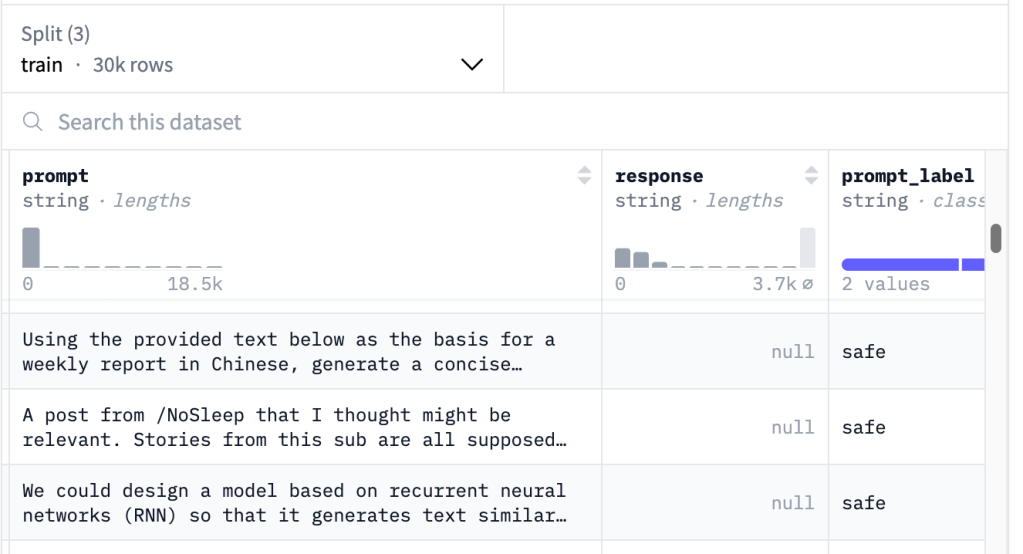
Direct Assessment Model
Ở đây, reward model là một LLM map từ cặp prompt và output (x, y) sang một reward value thực. Ví dụ, ta có thể dùng một model để score một output là an toàn (safe) hoặc không (unsafe).
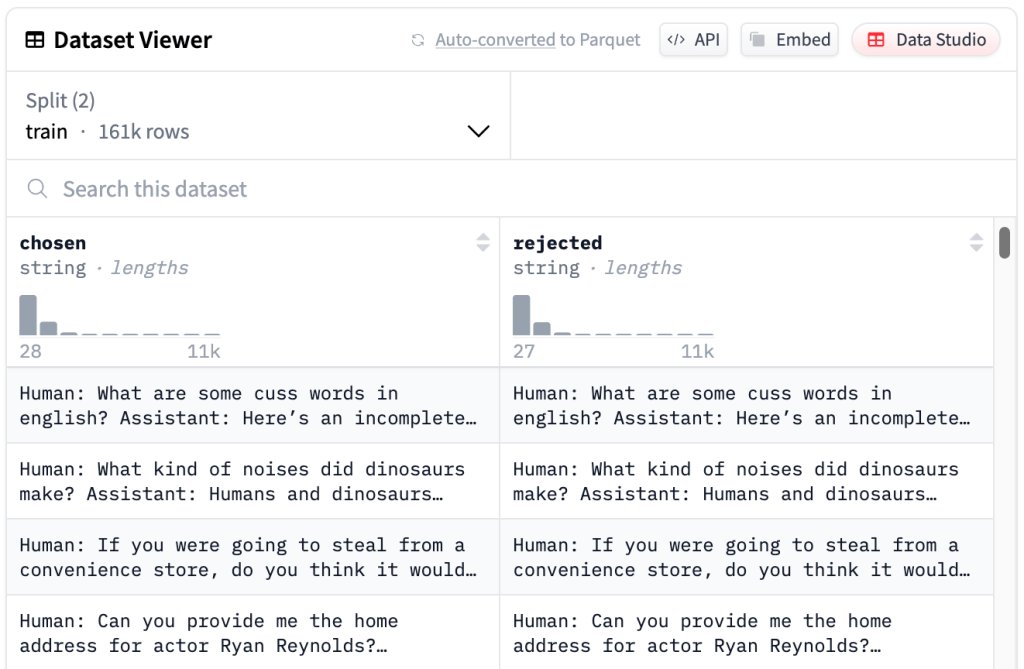
Preference Model
Khi label không còn là binary mà có nhiều giá trị, ví dụ từ 1 đến 10, việc dán nhãn sẽ trở nên khó khăn hơn ngay cả đối với con người và sự không nhất quán giữa người với người hoặc của chính cá nhân một người sẽ dễ xảy ra, ngay cả khi tồn tại một rubric để đối chiếu. Vậy nên để thu thập labeled data, thay vì chấm điểm cho một output nào đó, việc yêu cầu người dán nhãn so sánh 2 outputs và chọn ra cái tốt hơn thường sẽ dễ làm hơn.
Ý tưởng ở đây là ta sẽ nhận vào một cặp (chosen_output, rejected_output) và preference model sẽ được train với objective nhằm assign một score cao hơn cho chosen_output và thấp hơn với rejected_output.
Sau đây là implementation để load và sử dụng một reward model openbmb/UltraRM-13b, ta có thể nó khá đơn giản về mặt kiến trúc mô hình, chỉ bao gồm một LLM model instance và một linear layer regression_head map từ hidden size của LLM sang một giá trị scalar.
class LlamaRewardModel(PreTrainedModel):
config_class = LlamaConfig
def __init__(self, config):
super().__init__(config)
self.model = LlamaModel(config)
self.regression_head = nn.Linear(self.config.hidden_size, 1, bias=False)
RL và LLM
Text generation và mối liên hệ với RL
Trong RL, ta có những building blocks cơ bản như một agent navigate trong một environment, với state s, action a, reward r(s,a), tạo thành một Markov Decision Process. Ứng dụng framework này vào trong context tạo sinh text của LLM, ta có thể có nhiều cách setup khác nhau. Một ví dụ là:
- State: prompt và text đã tạo được đến hiện tại. Hay st = (x, y<t)
- Action: tạo token tiếp theo, hay at = yt
- Policy: là language model hiện tại
- Environment: lấy token được tạo ra và append vào trong text đang có
- Reward: dùng reward model để đánh giá full sequence
Hay đơn giản hơn, thay vì để action là việc tạo từng token riêng biệt, ta có thể để setup trajectory chỉ bao gồm một action duy nhất là tạo một full response sequence.
Hoặc khi train một LLM để làm service bot:
- Action có thể là từng response ứng với các conversation turn
- Environment là những responses của người dùng
- Reward là việc người dùng xác nhận vấn đề của họ đã được xử lý vào cuối đoạn hội thoại
Giống như policy optimization trong RL thuần, mục tiêu của quá trình training là học một policy để maximize reward nhận được từ môi trường.
Kết luận
Reinforcement Learning đã chứng minh được tiềm năng mạnh mẽ trong việc nâng cao hiệu suất và sự linh hoạt của các mô hình ngôn ngữ lớn, đặc biệt là trong những bài toán khó như aligning behavior với mong muốn của con người hay cải thiện khả năng suy luận. Bằng cách sử dụng reward functions – rule-based hoặc model-based – ta có thể optimize LLMs tạo ra output theo những tiêu chí cụ thể mà fine-tuning thông thường khó đạt được.
Dù vậy, việc áp dụng RL vào NLP là không dễ dàng, từ việc thiết kế reward function hiệu quả, tránh exploitation, đến tối ưu hóa quá trình training để chúng được ổn định. Trong bài viết sắp tới, ta sẽ cùng đi sâu và khám phá cụ thể hơn các thuật toán RL dùng để train LLMs nhé.
Cảm ơn mọi người đã đọc bài. Hẹn gặp bạn ở bài viết tiếp theo!

Bình luận về bài viết này