
- Giới thiệu
- Cơ bản về thuật toán MCTS
- MCTS giúp các LLM nhỏ đạt performance của LLM lớn hơn gấp nhiều lần
- MCTS và LLM Agents
- Kết luận
- 📚 Tham khảo
Giới thiệu
Thuật toán search là một lớp các kỹ thuật cốt lõi trong trí tuệ nhân tạo (AI), dùng để giải quyết các bài toán lên kế hoạch (planning) và ra quyết định (decision making) trong không gian trạng thái (state space) lớn – từ những bài toán kinh điển như tìm đường đi ngắn nhất hay trong game playing như chơi cờ,… Monte Carlo Tree Search là một trong số các thuật toán đó, với những điểm nổi bật khiến nó trở nên đặc biệt hơn so với các thuật toán search khác. Trong bài viết này, ta sẽ cùng đi qua cơ bản về thuật toán này, cũng như tìm hiểu những cách ứng dụng nó trong mảng NLP, cụ thể là LLMs và LLM agents.
Cơ bản về thuật toán MCTS
Monte Carlo Tree Search (MCTS) là một thuật toán tìm kiếm dựa trên heuristic theo hướng probabilistic sampling, được thiết kế để hoạt động tốt trong những không gian hành động lớn và sâu (ví dụ với một search tree có branching factor lớn), hay ở những bài toán mà ở đó ta khó có thể viết được một hàm đánh giá trạng thái (state evaluation) đủ hiệu quả để sử dụng với các thuật toán truyền thống như Minimax.
Một ví dụ điển hình mà ở đó, MCTS đóng vai trò quan trọng là bài toán game cờ vây (Go), với không gian trạng thái lớn hơn rất nhiều so với game như cờ vua. Trong khi ta có thể viết một hệ thống AI chơi cờ vua ở khả năng của con người với Minimax, cờ vây là một trò chơi khó hơn nhiều và mãi đến năm 2016, với sự ra đời của AlphaGo từ Google DeepMind kết hợp Deep Reinforcement Learning và MCTS, ta mới có một hệ thống lần đầu vượt qua con người ở bộ môn này.
Ở high-level overview, thuật toán này hoạt động như sau:
- Xây dựng một statistics tree, map từ một node sang giá trị ước lượng của node đó
- Statistics tree này sẽ hướng dẫn AI agent hướng đến những node có giá trị cao / thú vị trong game tree
- Giá trị của node trong statistics tree sẽ được xác định bằng việc chạy simulations
Đi vào cụ thể hơn, MCTS có 4 bước chính trong mỗi vòng lặp:
- Selection (Chọn nhánh): Bắt đầu từ node gốc, thuật toán chọn đường đi xuống search tree theo một policy nhất định, thường sử dụng công thức Upper Confidence Bound for Trees (UCT) để cân bằng giữa việc khai thác (exploitation) và khám phá (exploration)
- Expansion (Mở rộng): Khi đến một node còn child nodes chưa được expanded, thuật toán thêm một hoặc nhiều child nodes tương ứng với các hành động có thể thực hiện tiếp theo vào search tree
- Simulation (Giả lập): Từ child node mới được expand, thuật toán thực hiện một (hoặc nhiều) lượt mô phỏng ngẫu nhiên đến khi kết thúc trò chơi hoặc đạt được trạng thái mục tiêu
- Back-propagation (Lan truyền ngược): Kết quả của lượt simulation được lan truyền ngược từ leaf node về node gốc để cập nhật giá trị (ví dụ: số lượt thắng, lượt đi qua) nhằm cải thiện hiệu quả của việc lựa chọn nhánh, nodes ở những vòng lặp tiếp theo
Dưới đây là công thức UCT để tính cho child node i trong MCTS:

với:
- wi : tổng giá trị reward đến hiện tại của node i
- ni : số lần node i đã được visited. Trong bước MCTS simulation, nếu search path đi qua node i, ta sẽ tính đó là một lần visit.
- C : một hằng số cố định, quyết định mức độ exploration, thường là sqrt(2)
- Ni : số lần parent node của i đã được visited
Dưới đây là pseudo-code cho thuật toán:

Artificial Intelligence: A Modern Approach (4th edition), trang 209
và dưới đây là phiên bản đơn giản hoá mình nhờ Claude dịch sang Python để dễ hiểu hơn:
import math
import random
class Node:
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = []
self.visits = 0
self.wins = 0
self.untried_actions = state.get_legal_actions()
def select_child(self, exploration_weight):
"""Select a child node using UCT formula"""
return max(self.children, key=lambda c: c.wins/c.visits +
exploration_weight * math.sqrt(math.log(self.visits)/c.visits))
def expand(self):
"""Add a new child node to the tree"""
action = self.untried_actions.pop()
next_state = self.state.clone()
next_state.apply_action(action)
child = Node(next_state, parent=self)
self.children.append(child)
return child
def update(self, result):
"""Update node statistics"""
self.visits += 1
self.wins += result
def monte_carlo_tree_search(root_state, iterations, exploration_weight=1.414):
root = Node(root_state)
for _ in range(iterations):
# Selection
node = root
while node.untried_actions == [] and node.children != []:
node = node.select_child(exploration_weight)
# Expansion
if node.untried_actions != []:
node = node.expand()
# Simulation
state = node.state.clone()
while not state.is_terminal():
action = random.choice(state.get_legal_actions())
state.apply_action(action)
# Backpropagation
result = state.get_result()
while node is not None:
node.update(result)
node = node.parent
# Return best move
return max(root.children, key=lambda c: c.visits).state.last_action
MCTS giúp các LLM nhỏ đạt performance của LLM lớn hơn gấp nhiều lần
Một cách ứng dụng thuật toán MCTS trong LLMs là thuật toán MCT Self-Refine, dùng để tăng performance của LLMs trên các task liên quan đến mathematical reasoning như GSM8K, AIME,… Ở đây, nodes là các phiên bản khác nhau của câu trả lời, và edges là các quá trình cải thiện một câu trả lời sang phiên bản tốt hơn. Thuật toán gồm các bước:
- Initialization: bắt đầu với một seed answer, ví dụ như “I don’t know”
- Selection: sử dụng một value function Q để rank các answers chưa được expanded, tính giá trị UCT và từ đó chọn node có giá trị UCT cao nhất để qua các bước kế tiếp
- Self-Refine: bước này tương ứng với bước expansion. Answer được chọn ở bước trước sẽ được optimize sang một answer tốt hơn, sử dụng Self-refine framework. (Madaan et al. 2023). Quá trình này sử dụng một LLM, bắt đầu bằng việc tạo một critical comment cho answer hiện tại và sau đó cải thiện dần thành một answer tốt hơn.
- Self-Evaluation: bước này tương ứng với bước simulation, bao gồm việc chấm điểm câu trả lời đã được refined ở bước trước
- Back-propagation: giá trị của node với refined answer được propagated về node cha và các node liên quan ở phía trên. Nếu giá trị của node con thay đổi, giá trị của node cha cũng sẽ được cập nhật theo.
Code cho thuật toán này cũng được nhóm tác giả release trên GitHub.
MCTS và LLM Agents
MCTS cũng được áp dụng cho LLM agents như một cách để thực hiện test-time scaling. Bằng việc allocate thêm compute budget, LLM agents có thể khám phá những actions và trajectories khác nhau để chọn ra trajectory tốt nhất để hoàn thành nhiệm vụ đưa ra bởi người dùng.
Một ví dụ cho việc ứng dụng MCTS vào LLM agents là SWE-Search, một multi-agent framework sử dụng MCTS với cơ chế tự cải thiện (self-improvement) để nâng cao khả năng của LLM agents trong việc tự động xử lý repository-level coding tasks. Cụ thể, framework này bao gồm:
- Một SWE-agent cho việc exploration trên codebase, e.g., plan, search code, edits,…
- Một Value-agent để đưa ra feedback cho một action/observation nào đó. Agent này sẽ đưa ra một giá trị utility xấp xỉ cho một observation, cùng với giải thích ở natural language. Giá trị này sẽ được sử dụng để cải thiện việc đưa ra actions ở bước tiếp theo.
- Một Discriminator-agent để hỗ trợ việc tranh luận (debate) giữa các agents khác để cùng giải quyết câu hỏi nào đó (collaborative decision-making). Trong framework này, agent được sử dụng để chọn ra một output cuối cùng (một git patch) từ các outputs của các solutions khác nhau.
- Thuật toán Search: framework sử dụng một phiên bản chỉnh sửa của MCTS để thực hiện việc khám phá các trạng thái trong trajectory.
Dưới đây là diagram mô phỏng cụ thể hơn cách framework SWE-Search hoạt động, ta có thể thấy nó cũng bao gồm các bước quan trọng như Expansion thông qua việc tự refine actions và Evaluation, tương tự như thuật toán Self-Refine ở trên:
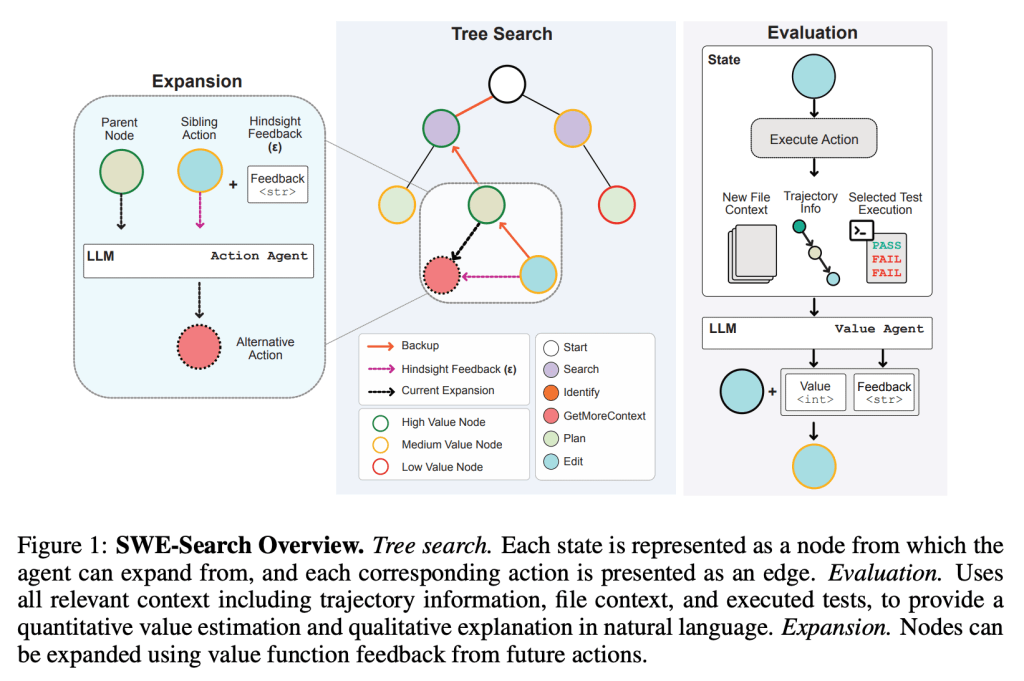
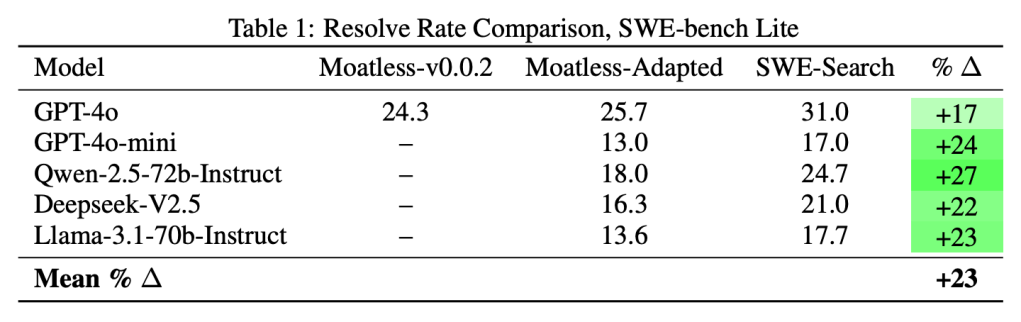
Việc ứng dụng SWE-Search giúp cải thiện 23% relative improvement trong performance trên SWE-bench – một benchmark test khả năng của LLM agents trong việc xử lý real-world repository-level issues – so với baseline agents không có exploration với thuật toán search. Code hiện thực của framework được nhóm tác giả release tại GitHub nếu bạn muốn tìm hiểu thêm.
Kết luận
Monte Carlo Tree Search (MCTS) là một trong những thuật toán search mạnh mẽ và linh hoạt, không chỉ ở các ứng dụng truyền thống như game playing mà còn đang được ứng dụng rộng rãi trong lĩnh vực NLP như LLMs và LLM agents. Bằng việc cho phép LLM khám phá không gian trạng thái theo xác suất, MCTS cho phép các hệ thống AI nhỏ hơn đạt được hiệu quả của các hệ thống lớn hơn, trong một số tasks cụ thể, thông qua cơ chế tự cải thiện. Trong bài viết này, ta đã cùng đi qua cơ bản về thuật toán cũng như các ứng dụng liên quan gần đây như MCT Self-Refine và SWE-Search.
Cảm ơn mọi người đã đọc bài. Hẹn gặp bạn ở bài viết tiếp theo nhé!

Bình luận về bài viết này